
Apache Griffin is an open source Data Quality solution for Big Data, which supports both batch and streaming mode. It offers an unified process to measure your data quality from different perspectives, helping you build trusted data assets, therefore boost your confidence for your business.
Apache Griffin offers a set of well-defined data quality domain model, which covers most of data quality problems in general. It also define a set of data quality DSL to help users define their quality criteria. By extending the DSL, users are even able to implement their own specific features/functions in Apache Griffin.
Apache Griffin had been accepted as an Apache Incubator Project on Dec 7, 2016.
Apache Griffin graduated as an Apache Top Level Project on Nov 21, 2018.
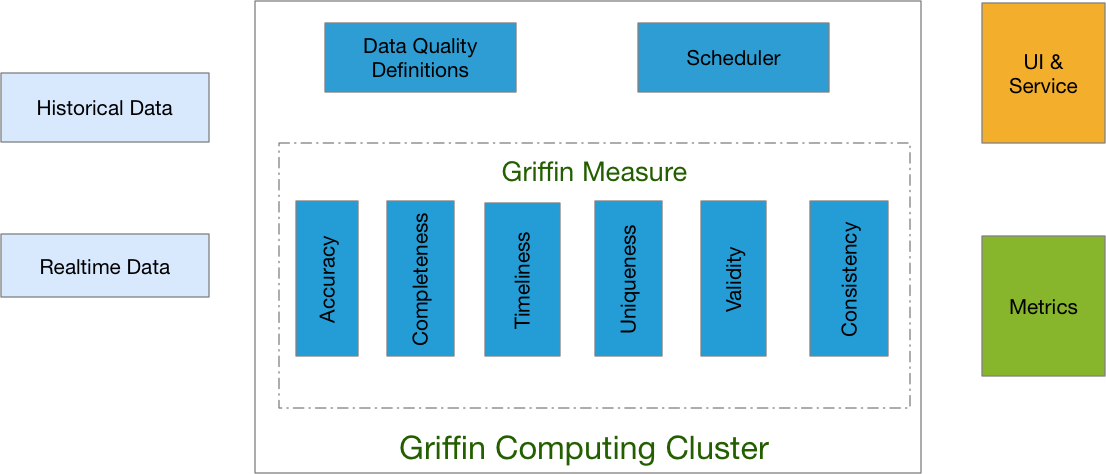
Apache Griffin handle data quality issues in 3 steps:
Data scientists/analyst define their data quality requirements such as accuracy, completeness, timeliness, profiling, etc.

Source data will be ingested into Apache Griffin computing cluster and Apache Griffin will kick off data quality measurement based on data quality requirements.

Data quality reports as metrics will be evicted to designated destination.

Apache Griffin provides front tier for user to easily onboard any new data quality requirement into Apache Griffin platform and write comprehensive logic to define their data quality.










Get help using Apache Griffin or contribute to the project
Learn more about Apache Griffin from Conferences
